

When I am consulted for automated testing projects, I often find that the teams are familiar with unit tests and whole-system tests (think end-to-end tests driven through the GUI, designed to replace manual tests). However I find that teams have trouble defining tests in between the sizes of “unit” and “everything”. Developers sometimes start from unit tests and make them a little bigger (e.g. “integration tests”), and testers often start from whole-system tests and make them a little smaller (e.g. API tests). This works fine when the system under test is small, but not so well when the system under test is very large.
As an example, let’s examine the architecture of a system I built with my Hogfish Labs co-founder called Fish2Duck. It’s a very small, simple architecture designed to take a duck as input and produce a fish as output. It has two mobile apps that connect via a REST API to a backend server. The backend server connects to a database and a 3rd party service.
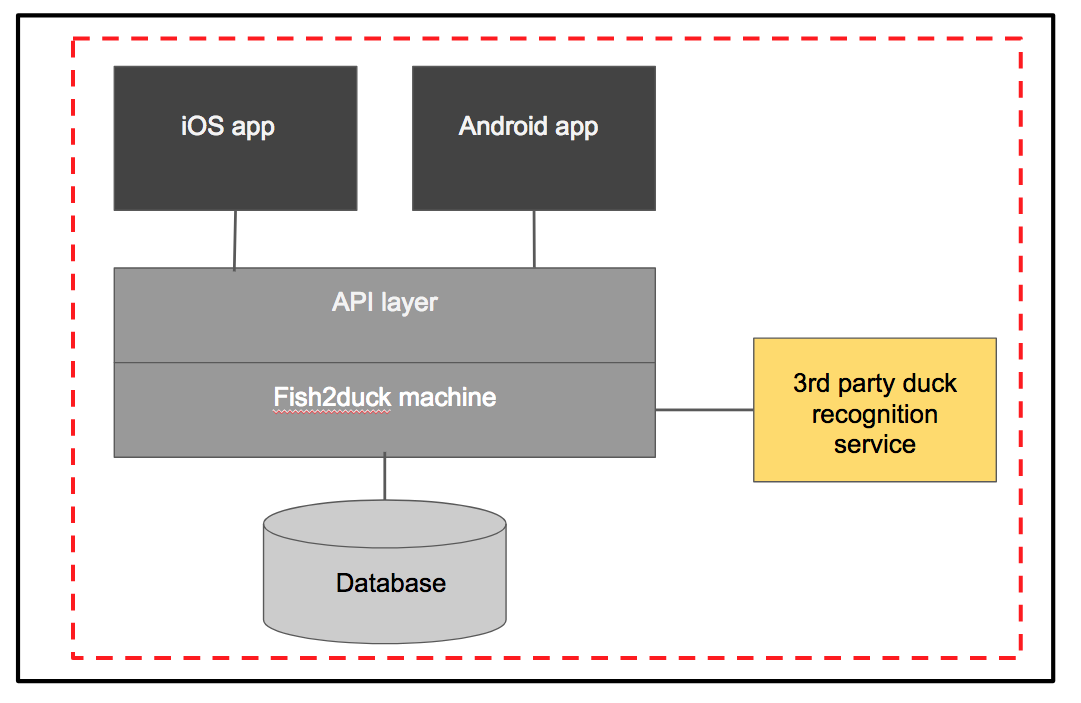
Say we were to create a suite of end-to-end tests to run against the whole system. We can represent the scope of these tests with the red dotted line. Let’s call this dependency scope, because it represents the amount of system dependencies contained in the system under test. We will create a suite of tests that exercise the iOS and Android apps via the UI, in an environment that lets these apps talk to a real API with a real fish2duck machine and database, and connects to the real 3rd party duck recognition service.
Now let’s say that we want to create a new suite of tests with a smaller dependency scope. We might want to do this because we have found that it’s difficult to debug backend problems whenever a bug is found in these large tests. So we create some API tests.
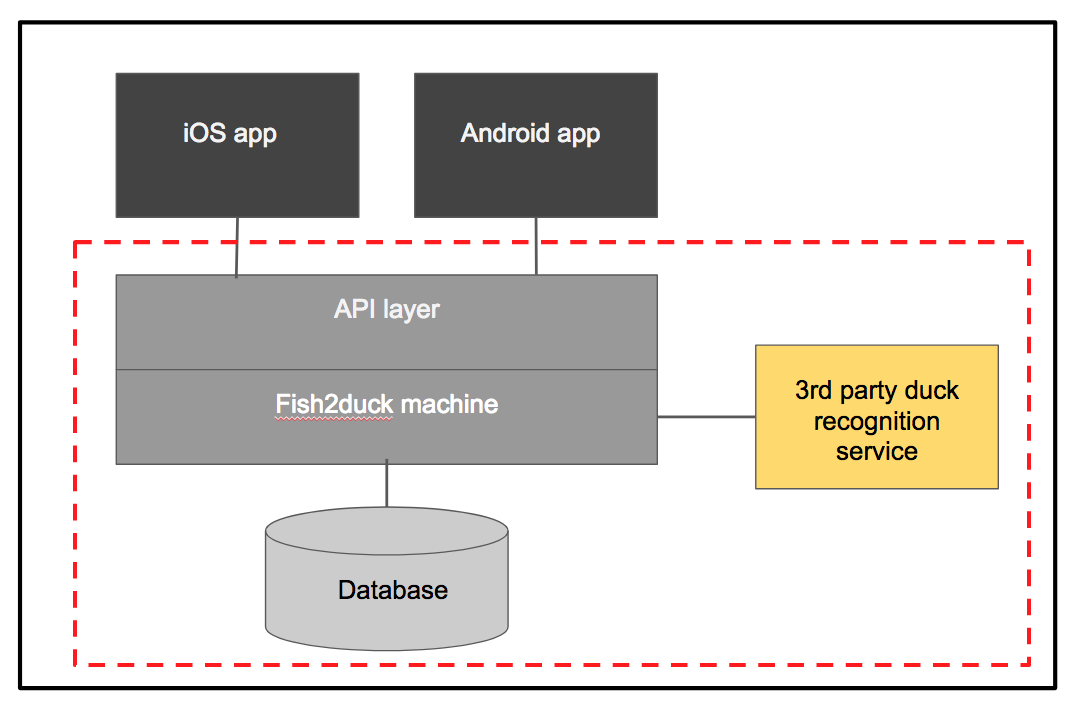
By doing this, we have significantly reduced the dependency scope. Now the system under test is just the API layer, fish2duck machine, database and 3rd party connection. If we were to count the amount of components covered, that’s reduced it from 8 components to 6. We could reduce the scope further, but we may find that for such a small system we are already finding it pretty easy to debug failures with this small dependency scope.
Now let’s examine a large, complex system. I don’t have an example to hand that I can use, so I have created an example based on several real-life systems I have worked with. Note the boxes at the bottom that contain even more boxes but were condensed for simplicity. If you’ve ever worked on a system this large, you might find that many architecture diagrams you are shown are oversimplified because the real one would require four-dimensions and so is impossible to represent on A3-sized paper.
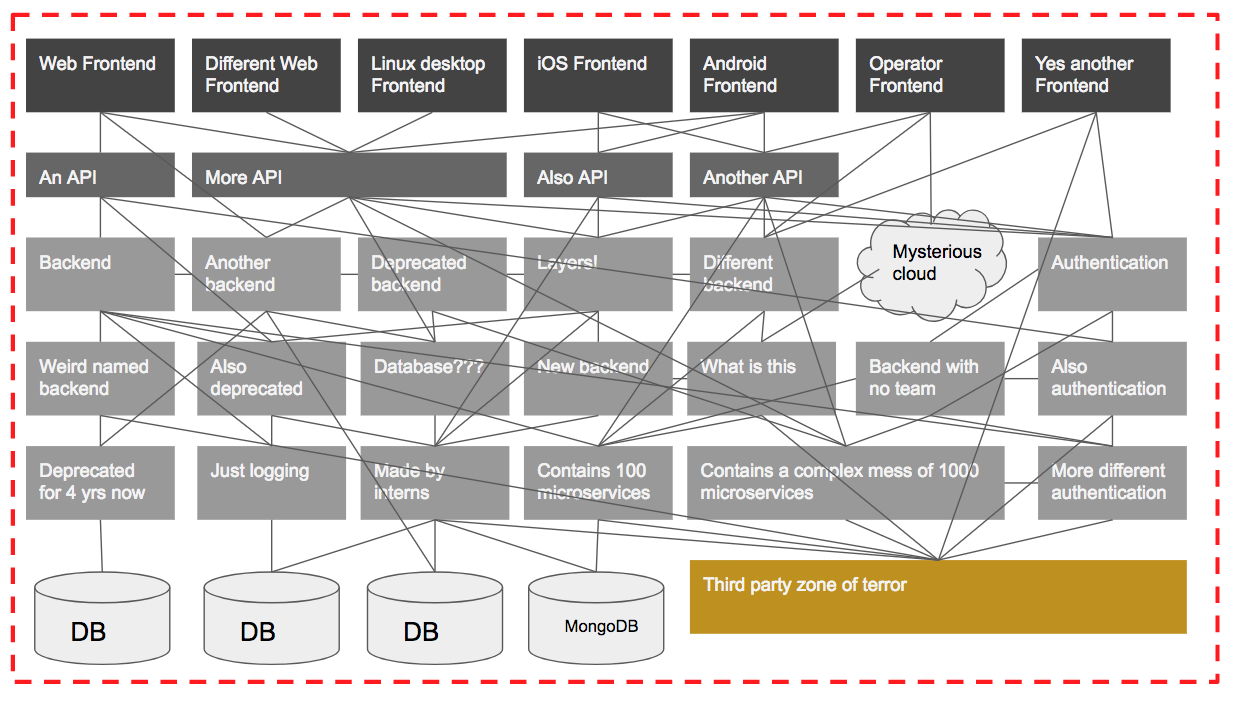
Let’s say we are assigned to a team that is in charge of testing the Web Frontend. We have created a suite of end-to-end tests that run against a test environment containing the entire backend system. That’s a lot of dependencies! With a system this large, testing the entire thing via the GUI becomes difficult for several reasons:
- Sometimes inputs are not injected via a UI. For example, a system that scrapes web data automatically.
- When a failure occurs in a system this large, it is very difficult to find the root cause. When every box on this diagram represents a different team responsible for it, this is even more difficult.
- When a problem occurs from testing a single endpoint, it is not always detectable from that endpoint. Monitoring the logs of every sub-system while testing the UI is not possible for a human being.
- In systems where operations can be slow and asynchronous, the effect is hard to correlate with the cause.
These problems are worse when the end to end full system testing is automated. With so many variables present in the system under test, full system tests driven via the UI are not equipped to cope with all of the problems they are likely to encounter, and even less equipped to cope with diagnosing the issues and presenting you with a useful report of the failure. “Could not find element on page” doesn’t tell you much when a race condition occurred three layers down because two tests running in the same environment happened to overlap when another scheduled job kicks off at 6.01am on a Tuesday.
So perhaps we try to reduce the scope by testing the API.
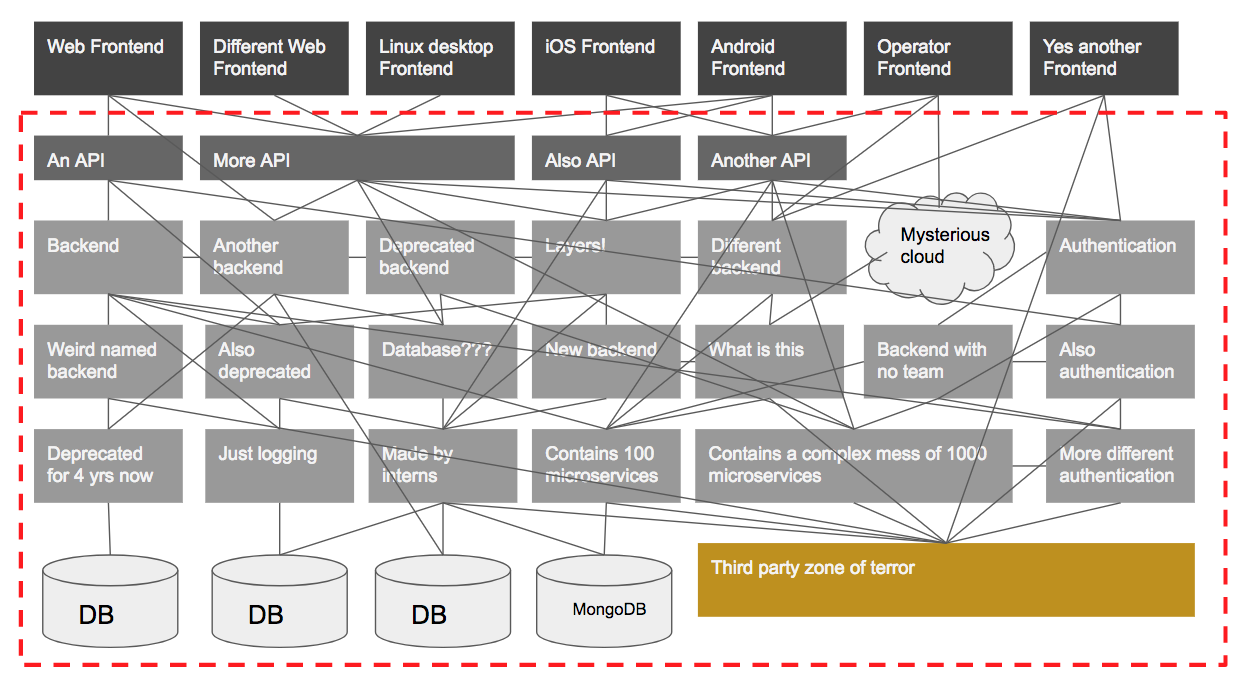
As you can see, this hasn’t done much more than shave off the top of the iceberg, so to speak. There are still so many components in this system under test that it’s very difficult to debug and find the root cause of failures. We have removed the complications of the UI, but all of our other problems are still present.
Meanwhile, developers may be creating unit tests and perhaps tests that are a little bigger than that. Representing these on the diagram above would look a little like this:

Wouldn’t it be great to meet in the middle?
The biggest cost of test automation is maintenance time. Maintenance time includes time spent:
- Debugging failures to figure out why they failed
- Fixing tests
- Re-running tests to see if they pass now that they’re fixed
- Fixing test environments
Maintenance time takes time away from release cycles. The goal of automated testing should be to make release cycles easier and faster. Getting the right balance of dependency scope for your test suites addresses these problems:
- Debugging failures is faster when there is less system under test to debug
- Fixing tests is faster when there’s less chance of failure due to a large, complex test environment
- Re-running tests is faster when there’s less system under test to boot up and test against
- Fixing test environments is faster when the environments are smaller and there’s no need to hassle another team for a fix
The last point is crucial for big systems. Playing the blame-game and negotiating fixes between teams is a huge time sink for large software groups. So when deciding how to scope tests, I suggest using the following guidelines:
- Scope tests just around the components that are maintained by the developers in your immediate team. This gives confidence in the work of your own team without the added complexity of changes from other teams.
- Create contract tests to verify that the systems owned by integrating components to ensure that they still send the data expected by your components.
- Test UI concerns independently from functional concerns.
- Eliminate the need for a network in your test environment.
If you are wondering how to isolate these components, this is done the same way that developers isolate components for unit testing – by using stubs, mocks and fakes. If you are a tester and you are unfamiliar with these terms, I strongly suggest that you learn about them. One of the best ways to learn is by writing unit tests using a tutorial like this one for Android.
So we may end up with some new test suites that are scoped a little like this:
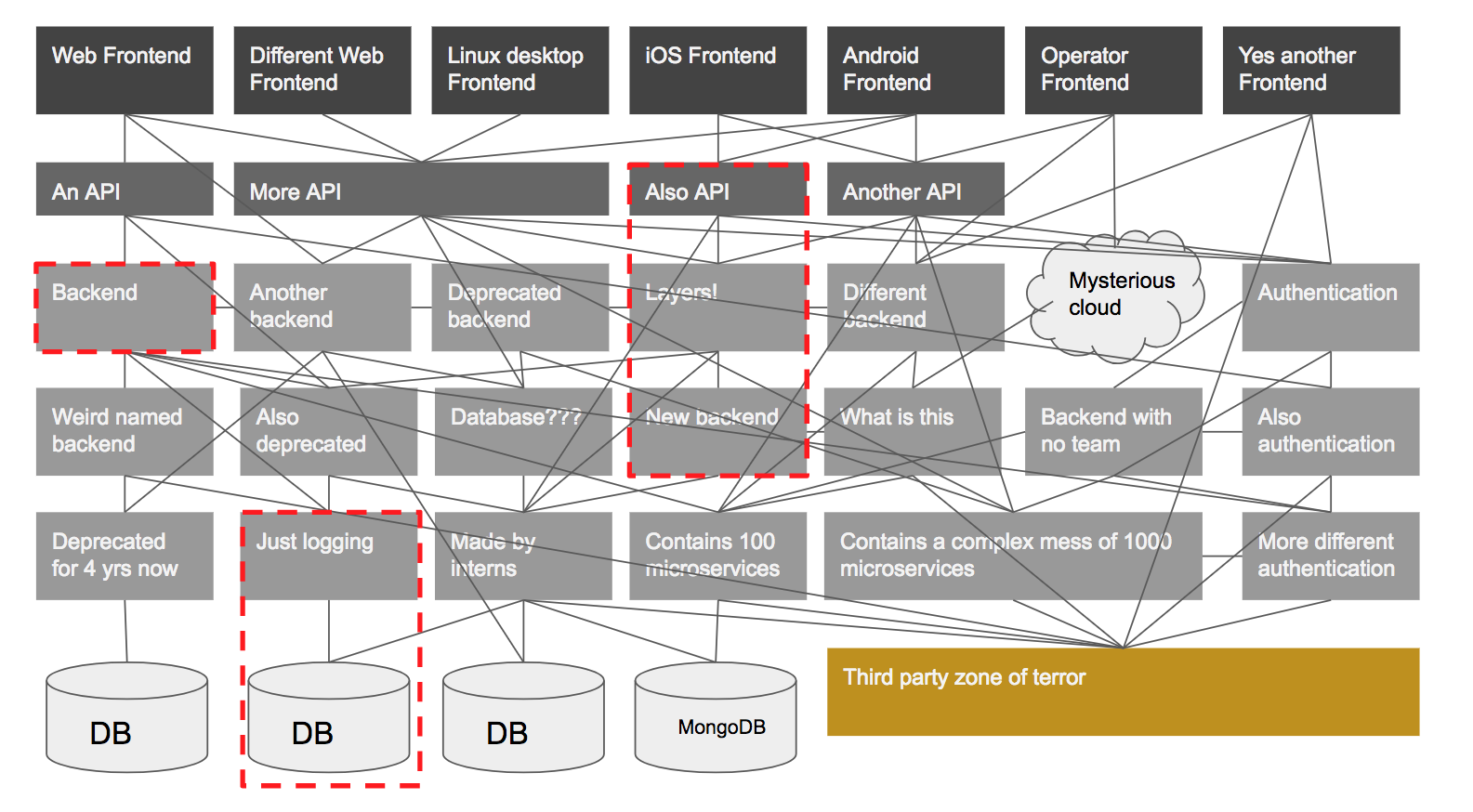
Where you choose to draw these boundaries depends very much on how your system is built and how the teams are structured. While I believe that it’s important for testers to be knowledgeable of this approach and to collaborate on the effort, the implementation of these tests is best suited to a developer because it requires good working knowledge of the system under test, and experience using stubs, mocks and fakes. Of course, someone who is strong in testing and development is the best fit for this task, often a senior developer.
Knowing how to scope tests to different sizes using dependency scope gives us the ability to create a series of test suites that give us confidence at each stage of the release pipeline. For example, we may end up with a suite of tests that runs in the following order for each release candidate:
- Lots of unit tests to ensure that units of code work as expected.
- A good amount of tests for the individual deployable component owned by the team, to ensure that anything that can be fixed by the team can be reported and fixed quickly.
- Some tests to ensure that the contract between the owned component and its neighboring components is still honored.
- Just a few of frontend-driven tests for sanity’s sake.
- A light, read-only probe in production to give confidence that the deployment has worked.
By increasing the scope at each stage we isolate any failures to the new level of integration points between dependencies. This makes it easier to track down the root cause of failures.
If your team could benefit from this approach and would like some guidance on how to implement it, please contact me directly to enquire about consulting.
2 thoughts on “Adjusting test size for large systems with dependency scope”
Comments are closed.